2025-2026 / UC Berkeley Capstone 121
Predict-Optimize E-Commerce Logistics
JD.com demand forecasting and multi-warehouse inventory optimization evaluated on cost, service level, and shortage risk
Overview
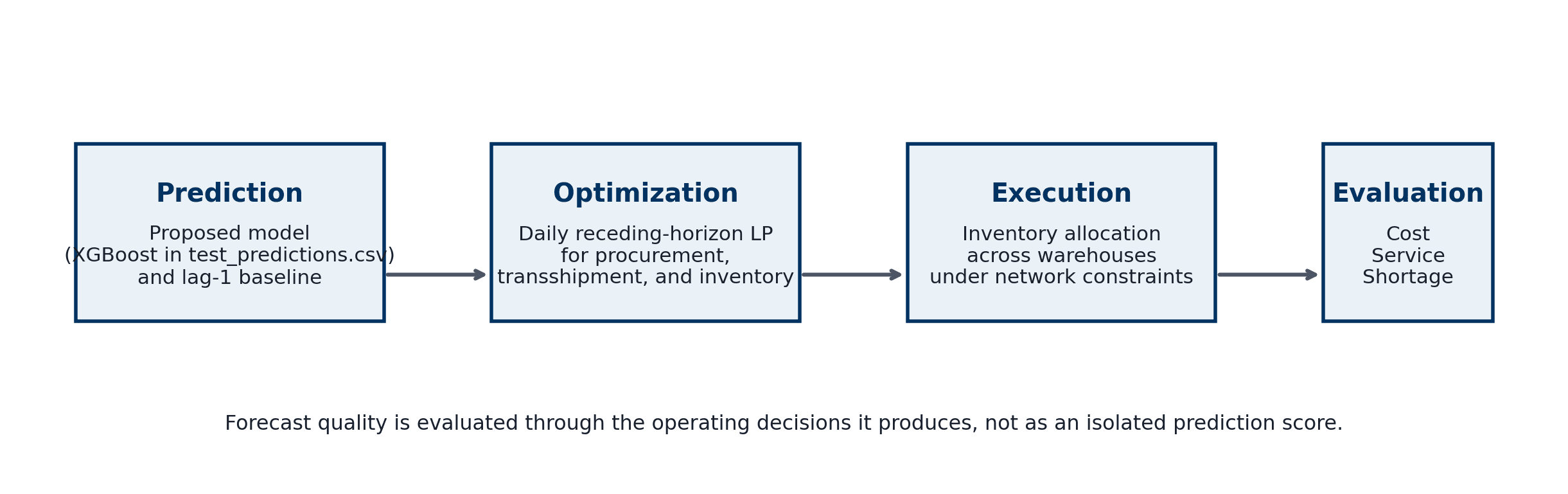
Built a decision-support pipeline that turns JD.com demand forecasts into daily procurement, transshipment, and inventory-positioning decisions for a multi-warehouse e-commerce network. The final report moves the project beyond a Newsvendor framing: it benchmarks six forecast candidates, harmonizes them onto the same warehouse-cluster test panel, solves a receding-horizon optimization model for each, and evaluates models by realized operating cost, service level, and shortage rather than forecast accuracy alone.
Problem
Large e-commerce networks often optimize forecasting and operations as separate stages. A model may reduce WAPE while still creating expensive inventory placement, cross-warehouse transfers, stockouts, or excess holding cost. The capstone asks which forecast should be trusted when the planner is accountable for operational outcomes, not just statistical fit.
Role
Team 121 capstone project - optimization and integration lead for parameter reconstruction, receding-horizon planning model, forecast-to-decision benchmark, final report figures, and technical synthesis
Timeline
Sep 2025 - May 2026
Tools
Python / pandas / XGBoost / LightGBM / Random Forest / Linear Programming / Receding-Horizon Optimization / LaTeX / Excel
Data
- JD.com March 2018 transaction-level research data covering orders, clicks, SKU attributes, users, delivery, inventory, and warehouse-network structure
- Training demand panel: March 1-24, 2018; test panel: March 25-31, 2018
- Forecast target: next-day demand at the warehouse-cluster level across a full 9,240-row test panel
- Candidate prediction files: XGBoost B, XGBoost C, LightGBM B, LightGBM C, RandomForest B, plus a lag-1 baseline
- Optimization parameters reconstructed from local artifacts: cluster prices, starting inventory, procurement eligibility, warehouse capacity, route feasibility, and delivery-time costs
Approach
- Harmonized all candidate prediction files onto the same warehouse-cluster-date target space, restoring 420 missing valid rows as explicit zero predictions so models were scored on identical realized demand
- Benchmarked forecast quality with WAPE, RMSE, MAE, bias, underprediction, overprediction, and weighted proxy costs
- Built a daily receding-horizon linear program that chooses procurement, transfers, ending inventory, and shortage under capacity, procurement eligibility, route feasibility, and delivery-time penalties
- Evaluated every forecast through the same optimization layer, then simulated realized demand to measure weekly cost, service level, shortage, overflow, transfer volume, procurement, and ending inventory
- Separated forecast fit from decision quality so the final recommendation could be grounded in the cost-service trade-off, not a single leaderboard metric
Evaluation
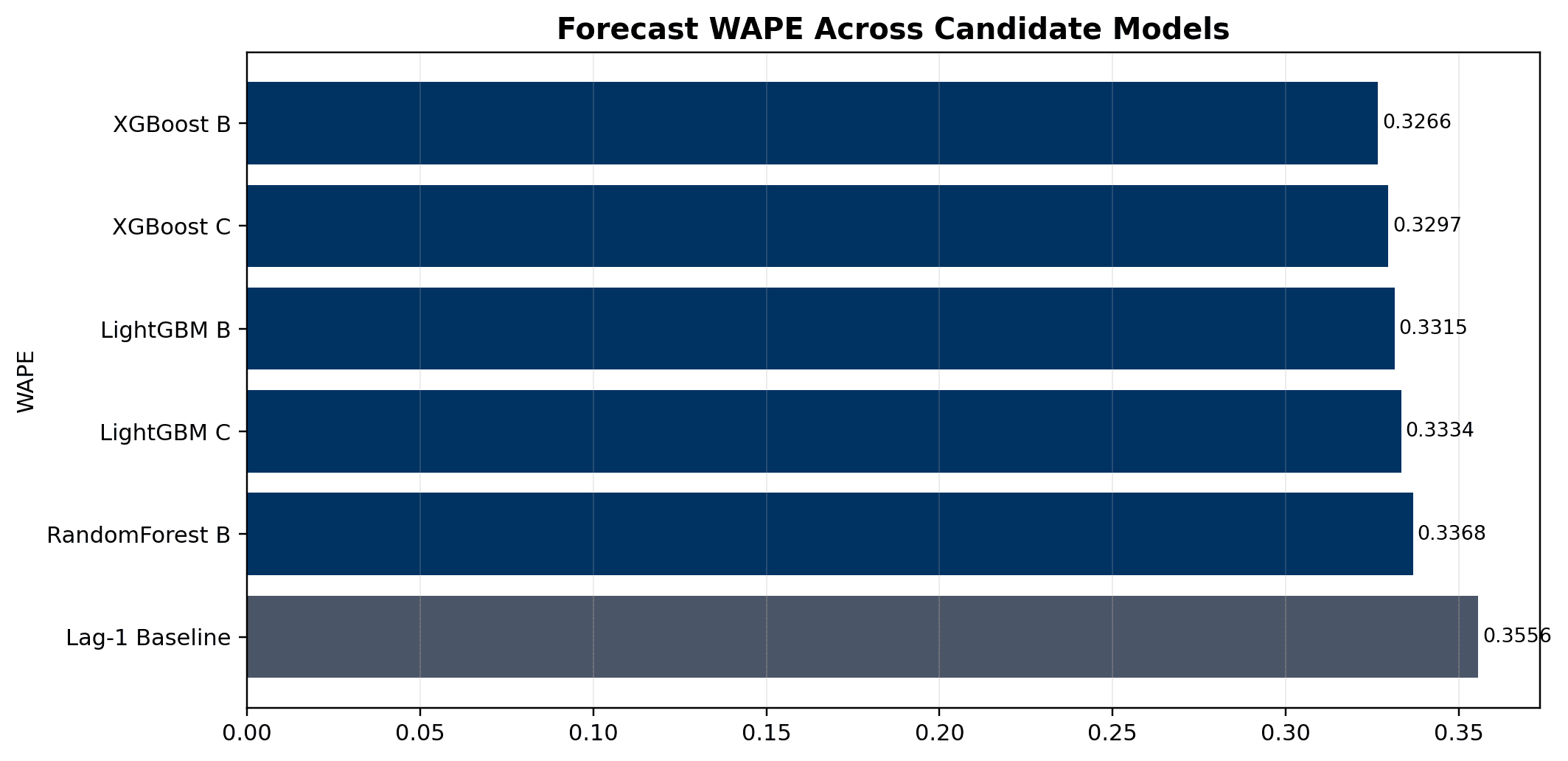
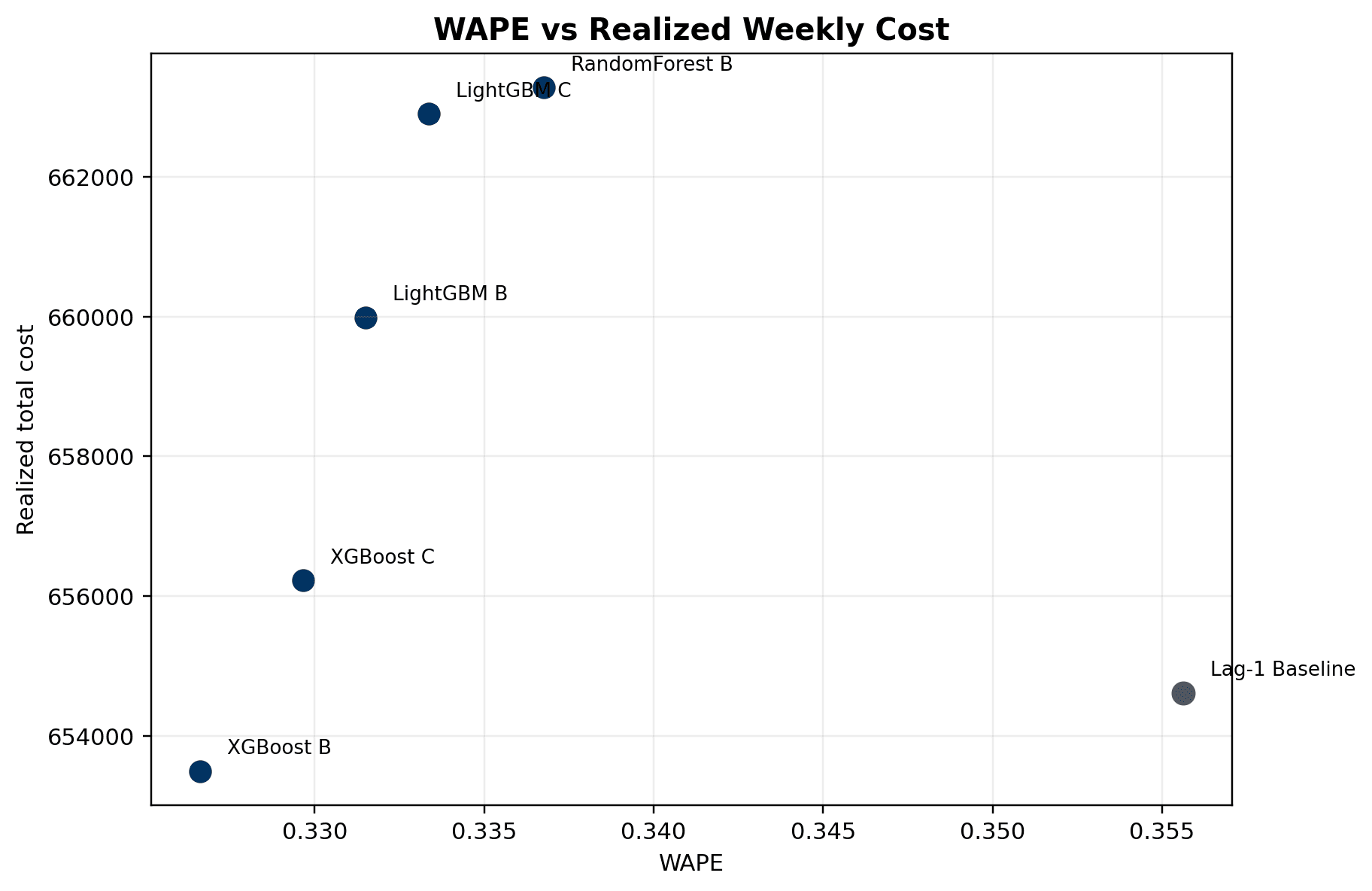
- XGBoost B led the final forecast benchmark with WAPE 0.3266, RMSE 18.9127, and the lowest weighted forecast proxy cost
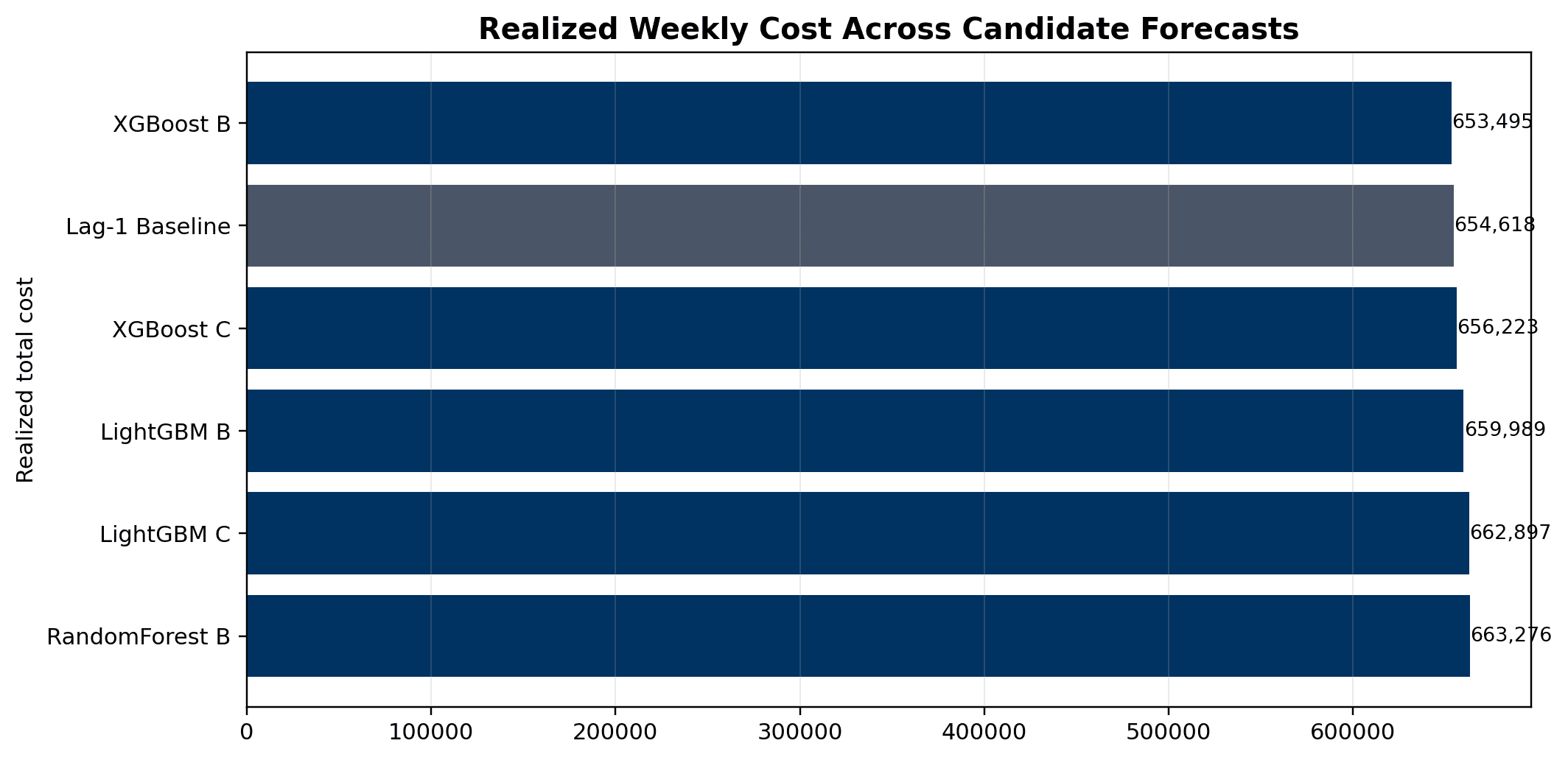
- XGBoost B also delivered the lowest realized weekly operating cost at 653,495.01 after optimization
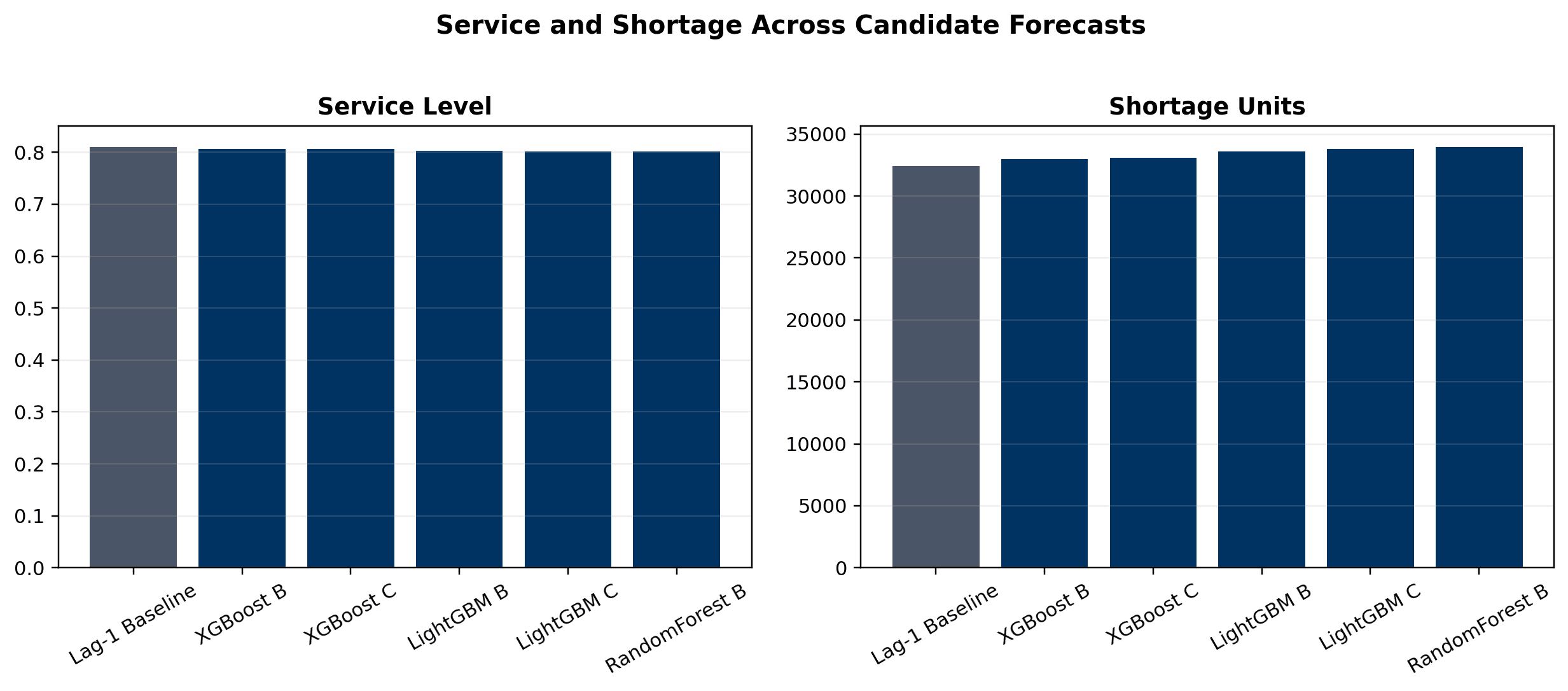
- Lag-1 baseline delivered the highest service level at 81.03% and the fewest shortage units at 32,395.39, making the cost-versus-service trade-off explicit
- XGBoost B service level was 80.69% with 32,979.03 shortage units, but it reduced transfer units, procurement units, ending inventory, overflow, and total cost relative to more conservative policies
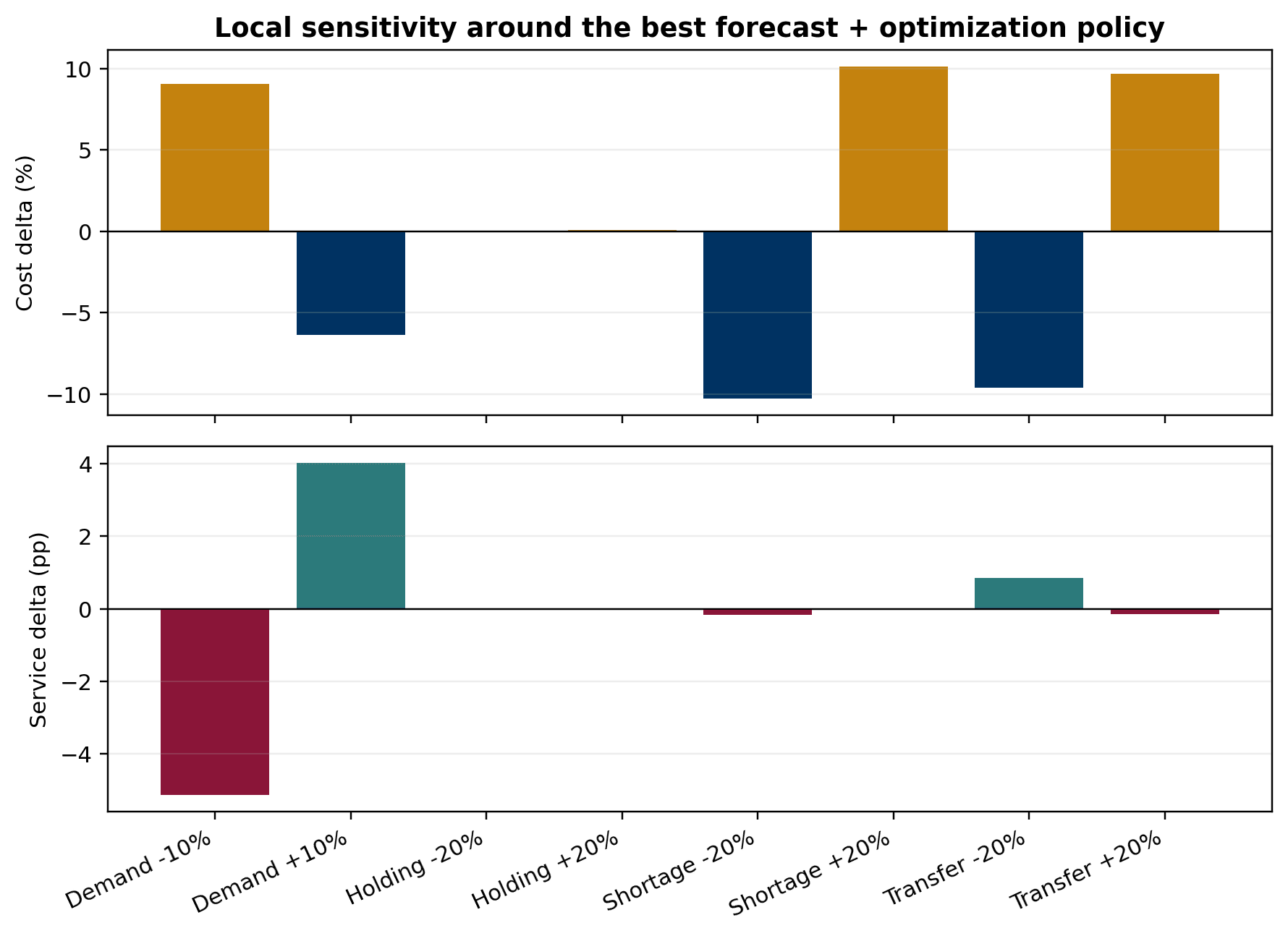
- Final report uses WAPE-versus-cost, service-versus-shortage, and optimization-cost figures to show why decision-aware evaluation is more useful than forecast metrics alone
Results
- Delivered a complete final report titled Integrating Demand Prediction with Inventory Optimization for E-commerce Logistics
- Built a practical predict-optimize-evaluate workflow for daily multi-warehouse planning
- Showed that the statistically strongest forecast and the most cost-efficient operating policy can align, while service level may still favor a simpler conservative baseline
- Quantified the operational consequence of forecast choice by running each model through the same constrained planning model
- Produced final report figures, candidate diagnostics, optimization summaries, parameter audits, and model comparison tables
Deployment
- Python scripts generate harmonized prediction panels, model ranking tables, optimization policy outputs, and report-ready figures
- Final PDF report and LaTeX source summarize the business context, technical workflow, benchmark results, limitations, and future work
- Pipeline artifacts include candidate forecast metrics, optimization metrics, daily policy summaries, sensitivity summaries, and parameter usage audits
- The workflow is suitable as a planning prototype: refresh forecasts, solve the daily LP, evaluate the realized policy, and compare model choices on operating outcomes
Limitations
- Evaluation covers a short March 2018 window, so results emphasize near-term recency rather than seasonal structure
- Initial inventory is proxied because the data does not provide a perfect warehouse-cluster inventory snapshot
- Warehouse capacity is reconstructed from observed inventory summaries with fallback logic for missing history
- Delivery time is modeled as a cost penalty rather than a full multi-period lead-time state transition
- Original raw SKU-to-cluster bridge is missing, so some price and inventory enrichment depends on saved mapping artifacts
Evidence
Repro Steps
- Use the final Capstone folder under Documents/Capstone, not the older portfolio copy
- Run the candidate forecast benchmark scripts to harmonize prediction files and regenerate ranking tables
- Run the optimization benchmark to solve the same receding-horizon LP for each forecast candidate
- Regenerate report figures from report_figures and results/optimization_prediction outputs
- Open the final report PDF for the complete written analysis and model tables
Next Steps
- Recover a native SKU-to-cluster bridge so prices, promotions, clicks, and inventory can attach directly to the provided clusters
- Replace proxy inventory initialization with a cleaner warehouse-cluster stock snapshot
- Extend the daily LP into a true multi-period optimization model with explicit inbound transfer and procurement lead-time carryover
- Evaluate alternative service targets and stockout penalties with a sponsor or domain expert
- Run a deployment-style rolling re-optimization study across more weeks to monitor forecast drift and policy drift